type
date
slug
status
summary
tags
category
password
icon
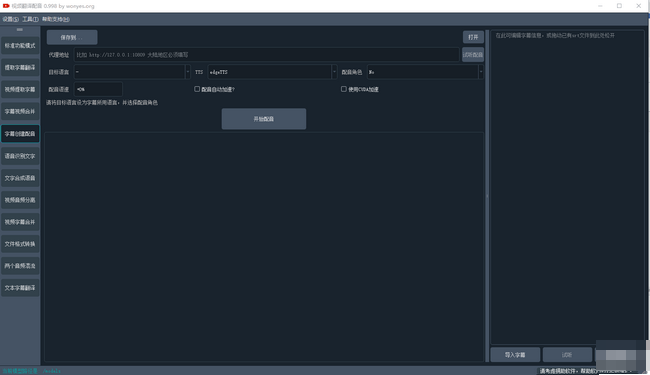
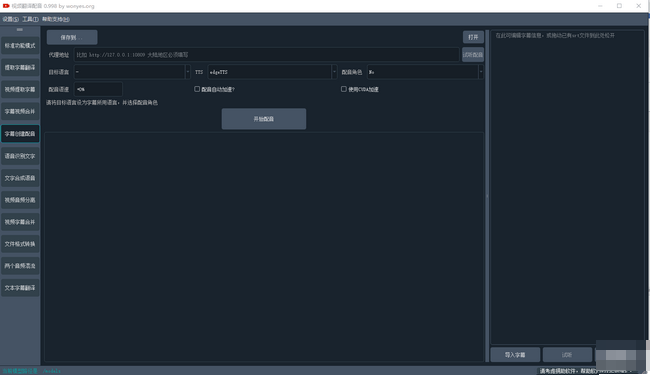
这是一个视频翻译配音工具,可将一种视频翻译为指定语言的视频,自动生成并添加该语言的字幕和配音。基于离线模型的语音识别faster-whisper。文字翻译支持google|baidu|tencent|chatGPT|Azure|Gemini|DeepL|DeepLX,文字合成语音支持Microsoft Edge tts Openai TTS-1 Elevenlabs TTS
使用方式
- 原始视频:选择mp4/avi/mov/mkv/mpeg视频,可选择多个视频;
- 输出视频目录:如果不选择,则默认生成在同目录下的_video_out,同时在该目录下的srt文件夹中将创建原语言和目标语言的两个字幕文件
- 选择翻译:任选 google|baidu|腾讯|chatGPT|Azure|Gemini|DeepL|DeepLX 翻译渠道
- 网络代理地址:如果您所在地区无法直接访问google/chatGPT,需要在软件界面比如网络代理中设置代理,若使用v2ray,则填写http://127.0.0.1:10809,若冲突,则填写http://127.0.0.1:7890。如果您修改了默认端口或使用的其他代理软件,则继续填写
- 视频原始语言:选择待翻译视频里的语言种类
- 翻译目标语言:选择希望翻译到的语言种类
- 选择配音:选择翻译目标语言后,可从配音选项中,选择配音角色;
硬字幕: 是指全部显示字幕,不可,如果希望网页中播放时也有字幕,请选择硬字幕嵌入
软字幕:播放器支持隐藏字幕管理,可显示或者字幕,该方式网页中播放时不会显示字幕,某些国产播放器可能不支持,需要将生成的视频同名srt文件和视频放在一个目录中下才会显示
- 语音识别模型:选择base/small/medium/large-v3,识别效果越来越好,但识别速度越来越慢,所需内存越来越大,内置base模型,其他模型请单独下载后,解压放到当前软件目录/models目录下。如果GPU显存低于4G,不要使用large-v3
整体识别/预先分割:整体识别是指直接发送整个语音文件给模型,由模型进行处理,分割可能更准确,但也可以制作出30秒长的单字幕,适合有明显静音的音频;预先分割时指先将音频按10s左右长度切割之后分别发送给模型处理。
- 配音速度:填写-90到+90之间的数字,同样的话在不同语言语音下,所需时间是不同的,因此配音后可能声画字幕不同步,可以调整此处语速,负数代表降速,正数代表加速播放。
- 音视频对齐:分别是“配音自动加速”和“视频自动降速”
- 静音分割: 填写100到2000的数字,代表毫秒,默认500,即以大于等于500ms 的静音分割为区间分割语音
- CUDA加速:确认你的电脑显卡为N卡,并且已配置好CUDA环境和驱动,则开启选择该项目,速度能大幅提升,具体配置方法见下方CUDA加速支持
- TTS:可用edgeTTS和openai TTS模型中选择要合成语音的角色,openai需要使用官方接口或者开通了tts-1模型的三方接口
- 点击开始按钮底部会显示当前进度和日志,右侧文本框内显示字幕
- 字幕解析完成后,将暂停等待字幕修改,如果不做任何操作,60秒后将自动继续下一步。也可以在右侧字幕区编辑字幕,然后手动点击继续合成
- 将在目标文件夹中视频同名的子目录内,分别生成多种语言的字幕srt文件、原始语音和配音后的wav文件,以方便进一步处理
- 设置行角色:可对字幕中的每行设定发音角色,首先左侧选好TTS类型和角色,然后点击字幕区右下方“设置行角色”,在每个角色名后面文本中中,填写要内容使用该角色配音的行号。 如下图:
- Author:205066
- URL:https://www.205066.xyz/article/videotrans
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!


